Building a Human-Centric AI Mental Health Chatbot
This is the story of UniMind — a student-facing mental-health chatbot we built at the University of Northampton. As part of our second-year group project module, we were given two main objectives:
- The chatbot should not attempt to solve problems directly, but rather signpost students to appropriate resources or provide supportive guidance.
- The chatbot must implement conversation planning to maintain a coherent therapeutic trajectory. This ensures that even during extended interactions, the conversation remains structured and goal-oriented, rather than devolving into disconnected, one-off responses.
It began as a rule-driven RASA assistant and grew into a safety-first, multi-agent AI that plans the conversation before it speaks.
How we started: bridging the support gap
University counselling teams work incredibly hard — and they’re also at capacity. Our goal with UniMind was not to replace clinicians but to offer safe, 24/7 first-line support that complements existing services and seamlessly routes students to real help. The final system hits those targets across multiple metrics — including layered crisis detection with ~99.99% reliability (internal) (100% on our scenario set; ≥99.9% with a single-provider outage; ~99% worst-case local fallback), 8.2/10 satisfaction, and an ~89% cost reduction.
Phase 1 — The legacy RASA approach (and what it taught us)
We began with a conventional RASA stack and built a deep intent hierarchy (200+ intents) with stories covering crisis indicators, academic stress, finances, relationships and campus services. In controlled tests we reached 100% story-level accuracy, but real-input intent classification averaged ~5.24%, a critical limitation for this domain.
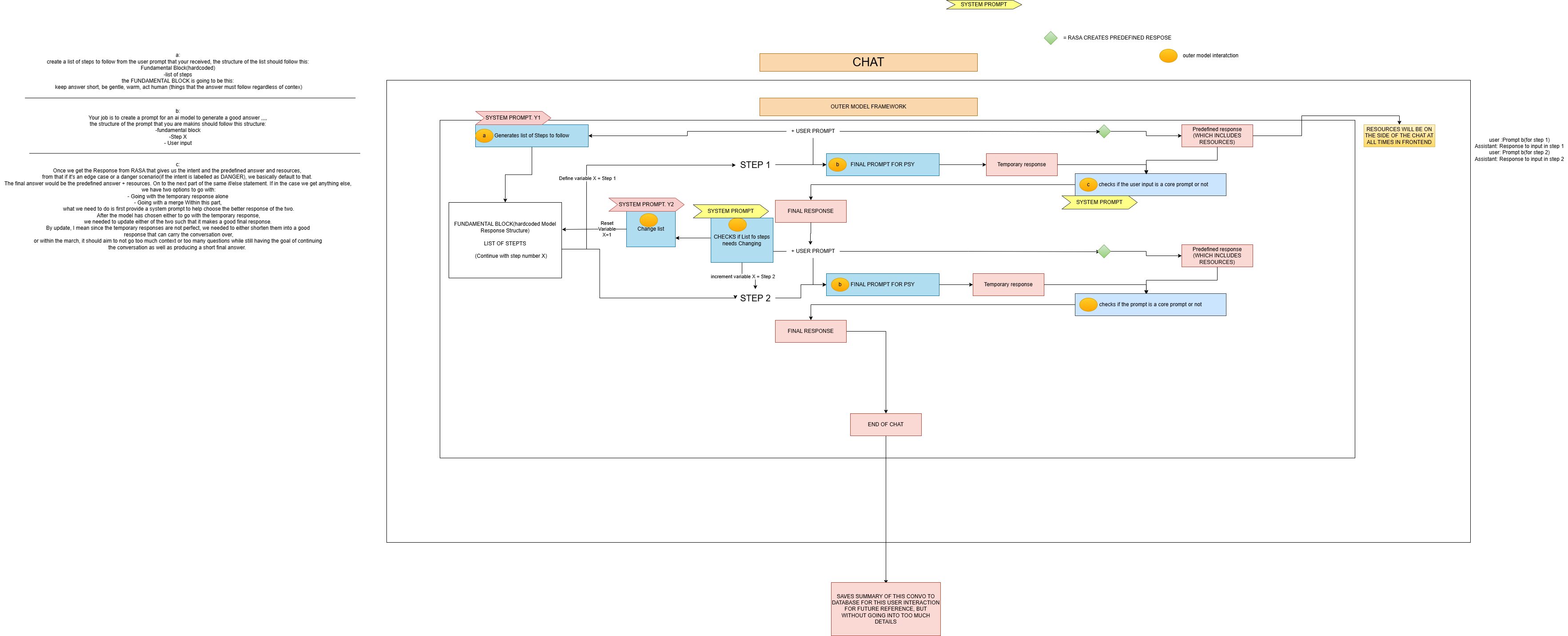
Phase 2 — From rules to reasoning: the multi-agent redesign
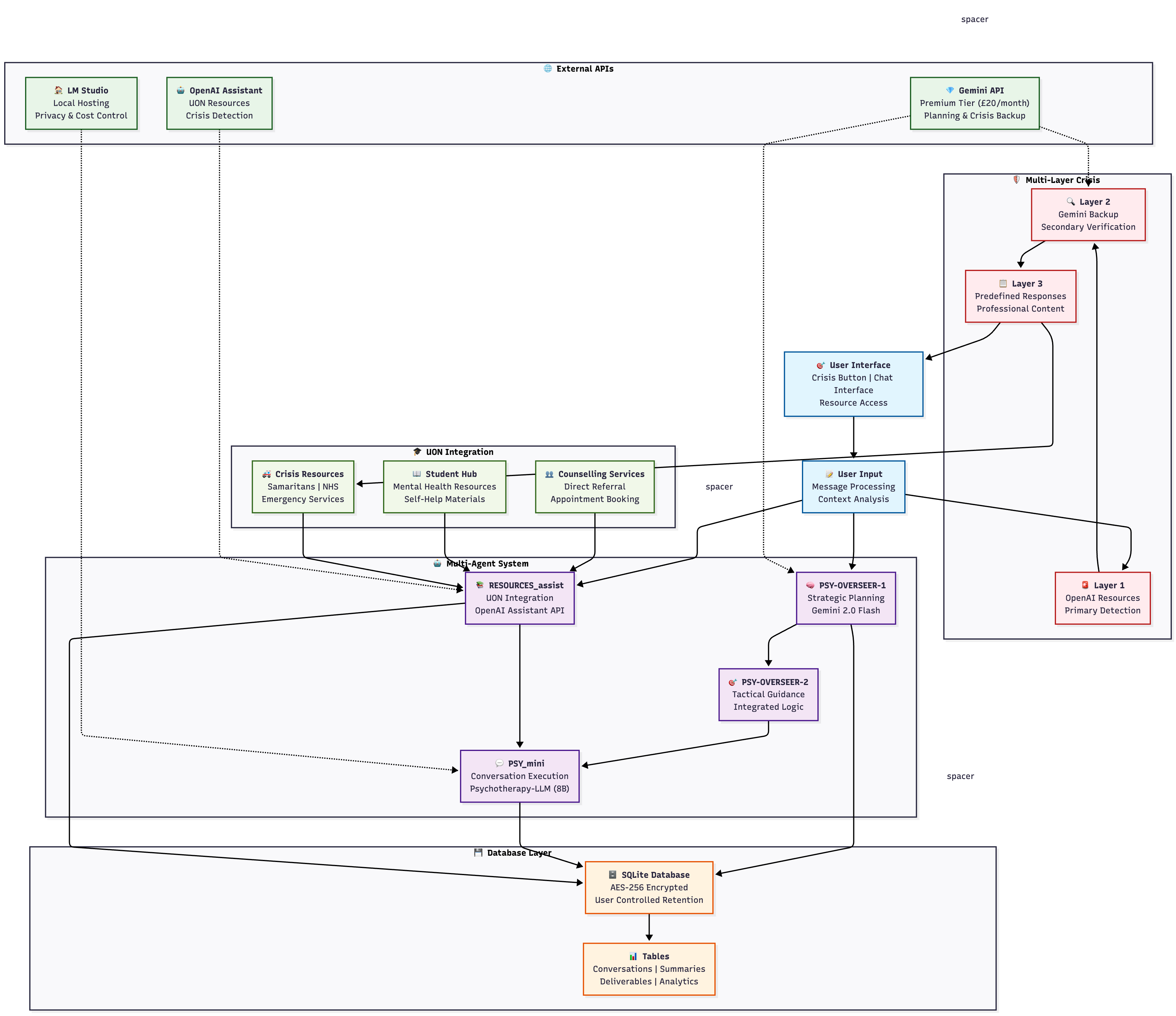
We rebuilt UniMind as a three-agent therapeutic architecture:
- PSY-OVERSEER-1 (Planner) — proposes a short plan for the next step(s) of the conversation (Initial → Assessment → Treatment).
- PSY-OVERSEER-2 (Guidance) — translates each plan step into micro-instructions.
- PSY_mini (Conversationalist) — a psychotherapy-tuned LLM that speaks in a warm, concise style, under strict safety and tone rules.
Agent Responsibility Matrix
| Agent | Primary Function | Technology | Input | Output |
|---|---|---|---|---|
| PSY-OVERSEER-1 | Strategic Planning | Gemini 2.0 Flash | User conversation + context | Therapeutic plan steps |
| PSY-OVERSEER-2 | Tactical Guidance | Integrated | Plan step + user state | Response guidance |
| PSY_mini | Conversation Execution | Psychotherapy-LLM (8B) | Guidance + user message | Empathetic response |
| RESOURCES_assist | University Integration | OpenAI Assistant API | Conversation content | UON resources |
Assignment principles — plan-first, referral-first, keep the conversation going
- Plan-first, not fix-first. First three steps focus on rapport/validation and basic emotional assessment — Stage-Based Planning Framework p.15.
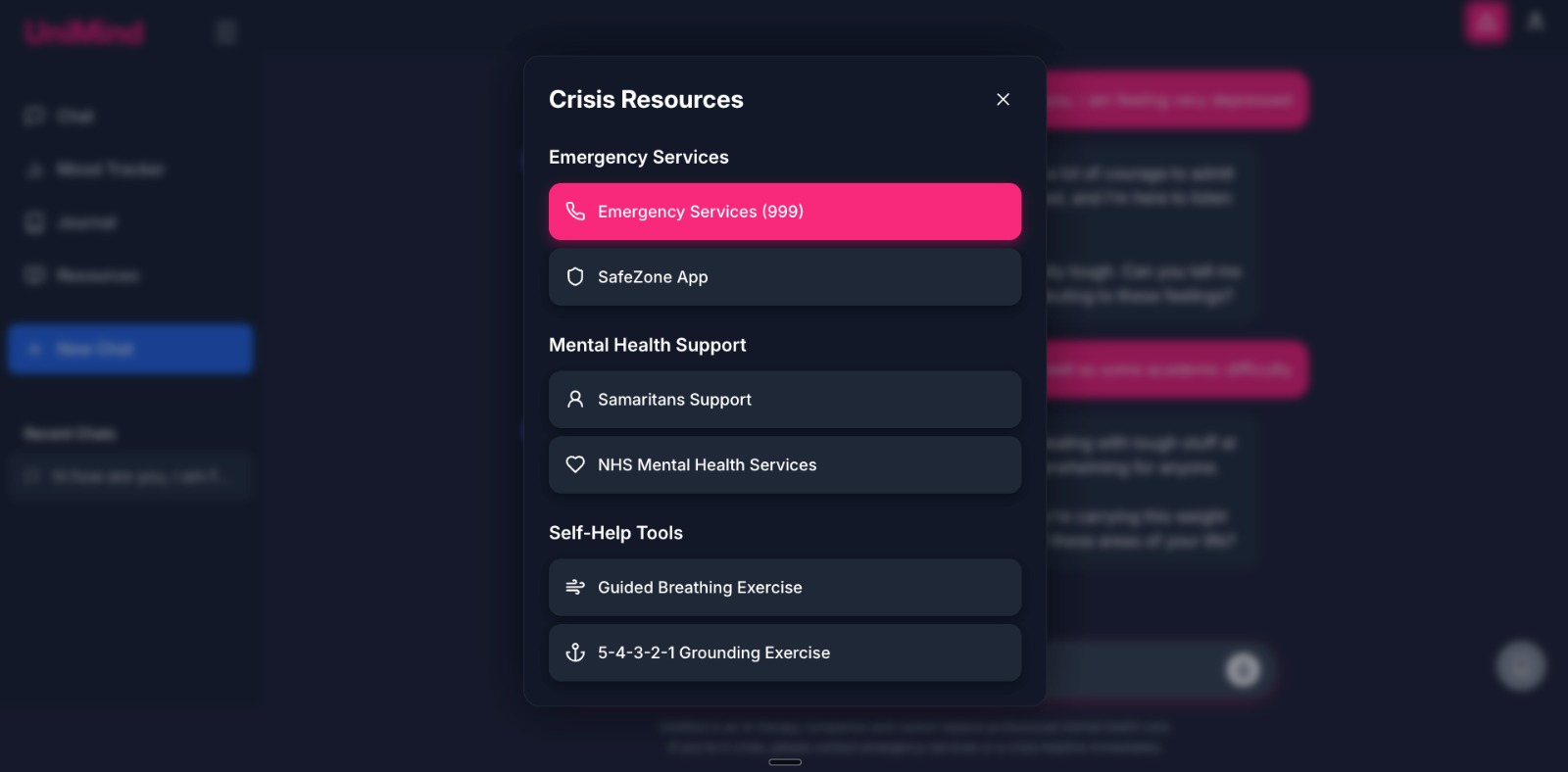
- Referral-first. Suggest courses of action and relevant resources; immediate signposting in potential crisis — Crisis Protocol p.18 (Fig. 2).
- Conversation continuity. Conversation Continuity Framework with Dynamic Plan Alignment and Three-Stage Progression — pp.17–18.
Data foundations — Kaggle in, student-relevant out
We curated therapist dialogues and mental-health Q&A from public datasets, cleaned for student themes. Cleaned CSVs drive prompt design, evaluation scenarios and guidance structure.
Making “helpful” feel human — style & safety by design
A strict system prompt set a warm persona, kept replies short and added a safety override for crisis language. An action threshold delayed concrete skills/advice until sufficient understanding.
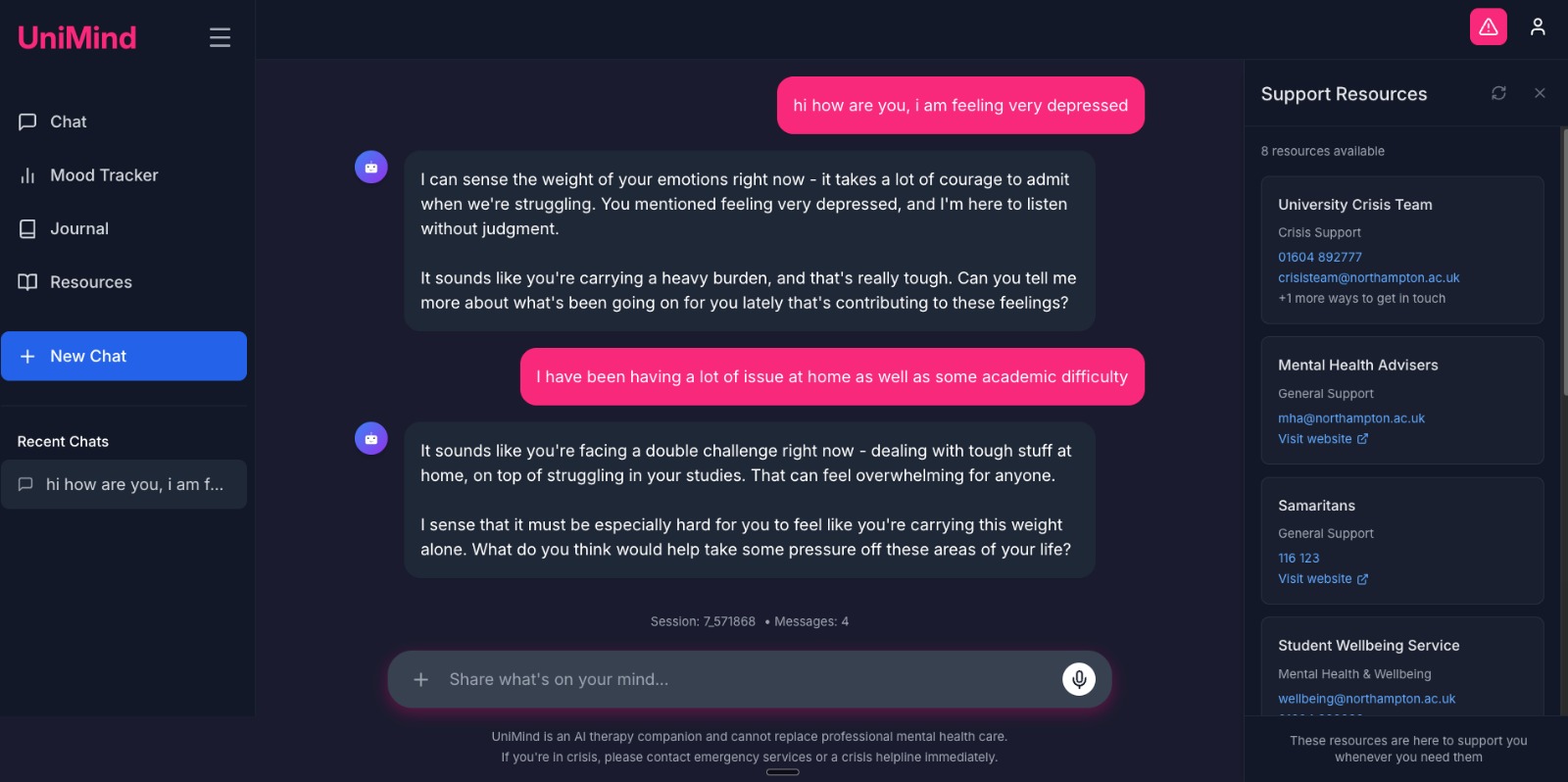
How we measured progress — cycles, rubrics, and evidence
Evaluation covered quantitative and qualitative signals across internal sessions, a public demo, and external participants. Reliability and performance summaries are detailed in the technical report.
Prompt-design analysis (pre-evaluation)
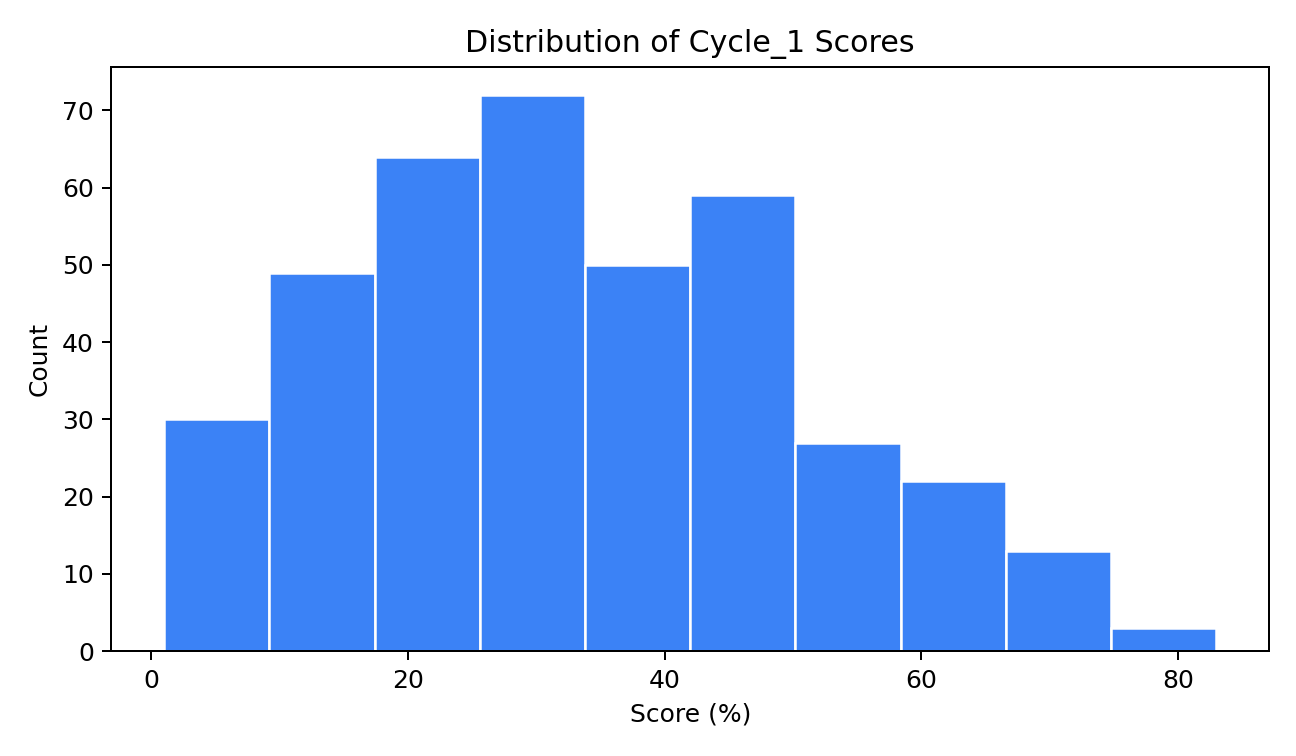
We first analysed Kaggle‑curated conversations and used an LLM scorer to rank micro‑elements (validation, reflection, open question, psychoeducation→application, tone, list‑avoidance). Those insights seeded our initial system prompt and micro‑structure before iterative evaluation and tuning.
We chose this quantifiable route so changes could be defended with data rather than handcrafted rules. Using base data comparisons (original therapy vs student responses) and the exported metrics (results.json, student_results.json), we targeted the upper quartile for human‑likeness and tone, then encoded the highest‑impact micro‑elements into guidance. See analysis assets in the repo’s Analysis_of_Test_Cycles.
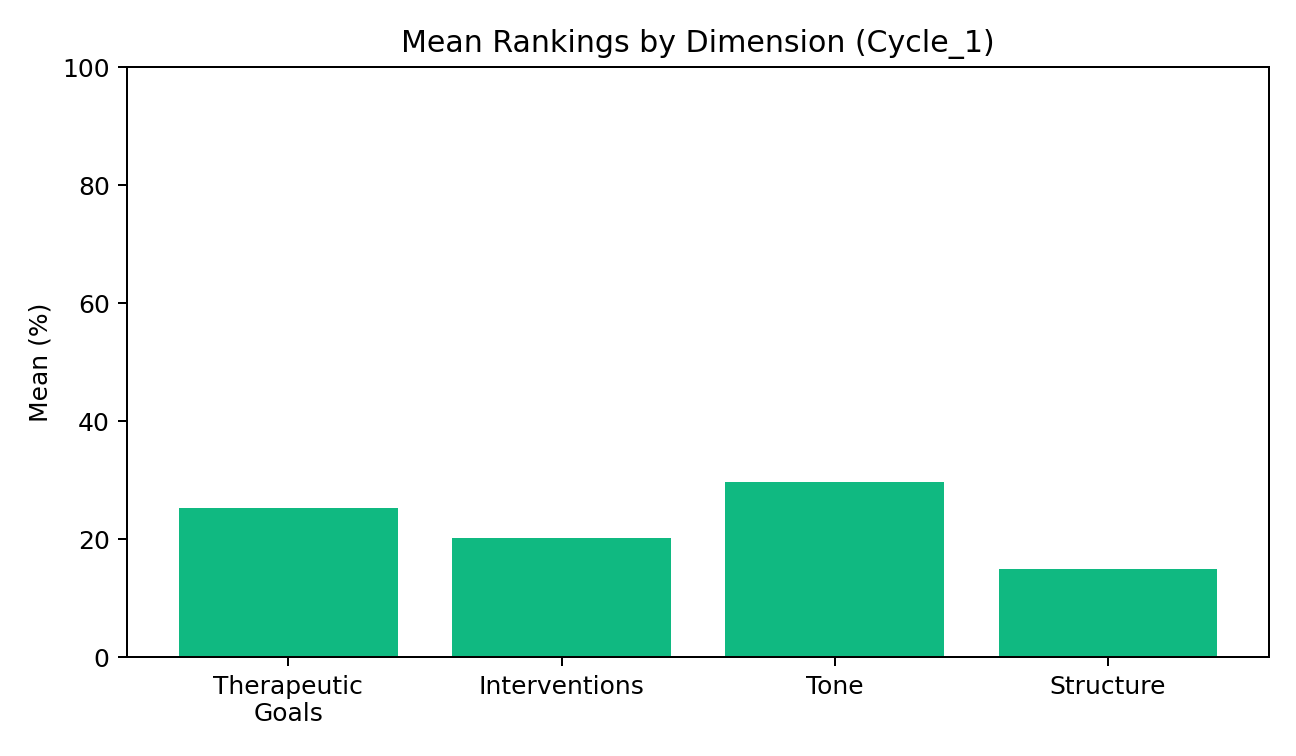
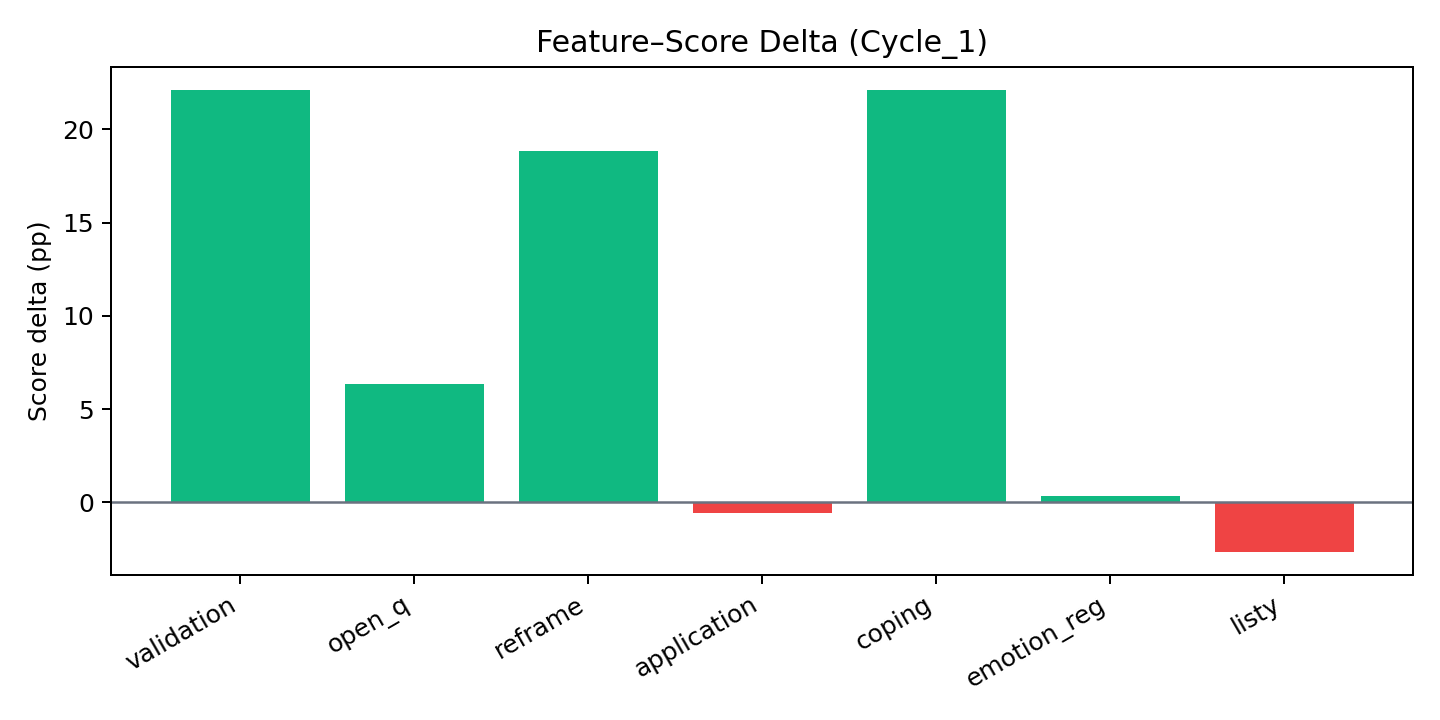
Therapy session feedback (evaluation notes)
Short therapy‑style test sessions provided qualitative checks on warmth, brevity and progression, plus safety behaviour under crisis language. We used these logs and reports to refine style guards, the action threshold and plan transitions. Session artefacts live in experiments/therapy_sessions and the framework notes in psychocounsel_testing_framework.md.
Model strengths & weaknesses
| Type | Detail |
|---|---|
| Strength | Multi‑layer crisis safety (deterministic crisis copy + layered detection); warm, concise tone with structured micro‑moves (validate → reflect → single open question → optional psychoeducation‑to‑application); clear plan stages; UON resource integration. |
| Strength | Neutral, jargon‑free language aiding inclusivity; consistent structure reduces ad‑hoc bias; explicit safety overrides. |
| Weakness | UK/UON‑centric resources by default; needs broader localisation for non‑UK contexts and international students (including crisis lines and services). |
| Weakness | Prompts lack explicit cultural‑sensitivity cues; missing gentle checks for cultural/identity context when relevant. |
| Weakness | Occasional edge‑case tone misreads (e.g., “disrespectful” perception) and handling of abrupt topic shifts; plan‑alignment smoothing needed. |
What needs to be done
- Broaden resource localisation beyond UON/UK; add global crisis lines and international support pathways.
- Add explicit cultural‑sensitivity probes in prompts; allow gentle checks for background/context when appropriate.
- Refine language guards to avoid tone misreads; improve handling of abrupt topic shifts; smooth dynamic plan alignment.
- Reduce cold‑start via pre‑warming/connection pooling; hold ≈2.5 s warm‑path responses under load.
- Capture structured per‑session feedback; monitor action‑threshold effectiveness; investigate previously observed empty logs; strengthen GDPR logging/analytics for deployment.
See supporting analyses: Model_Bias_Analysis.md, Model_Inclusivity_Analysis.md, and Therapy_Session_Summary.md.
User feedback & next steps
- User feedback (final system): external student testing averaged 8.2/10; feedback highlighted understanding/empathy, appropriate response quality, and a calming UI; follow‑up questions felt natural; a small number flagged tone edge‑cases in specific turns.
- Performance notes: public demo showed ~20 s cold‑start then ~9 s warm responses; current optimised stack targets ≈2.5 s on warm paths.
- Improvements in progress: pre‑warming and pooling to reduce cold‑start spikes; broadened resource localisation; explicit cultural‑sensitivity cues in prompts; continued tuning of action‑threshold and plan alignment; structured feedback collection in sessions.
- Deployment: web deployment work is active to make the system publicly accessible, alongside GDPR controls, monitoring, and reliability targets.
Results (prototype stage)
- Layered crisis detection: ~99.99% reliability (internal) with 100% on our scenario set; 99.9% with a single-provider outage; ~99% worst-case local fallback (OpenAI 94%, Gemini 96%, local 88%; Table 2, p.24; Table 3, p.28).
- Satisfaction: 8.2/10 (Table 3, p.28).
- Latency: ~9s warm on early demo; ≈2.5s optimised (p.25 and Table 3, p.28).
- Cost: £13.36 per user/month (~89% reduction) — p.26 and Fig. 5 on p.27.
Technical addendum (from cycle insights)
- Micro-structure enforcement: PSY-OVERSEER-2 guidance always yields validation → reflection → optional psychoeducation-with-application → one open question.
- Action threshold gating: Coping/homework appears only after sufficient exploration progress to avoid premature advice.
- Stage transitions: Fixed initial plan then automatic Initial → Assessment → Treatment progression with dynamic plan alignment.
- Lightweight eval harness: Internal scoring correlated with the micro-elements above; details in the repo Cycle Insights report.
Productisation tracks (you can try the front-ends)
RASA → multi-agent pivot
Earlier demo-day numbers (~9s average response and RASA limits) explain the pivot. Current stack returns ~2.5s on warm paths while preserving safety.
What surprised us
- Structure liberates. Plan + micro-structure improved naturalness — pp.17–18.
- Patience is programmable. Action-threshold gating raised perceived empathy — pp.23–24, 28.
- Safety must be multi-layered. Crisis handled by predefined copy — p.18 (Fig. 2).
Roadmap
- Push cold-start lower; 2–3s consistent responses
- Auto-tag micro-elements for QA
- Outcome tracking (opt-in), human-in-the-loop audits
- Voice/multilingual modes within safety envelope
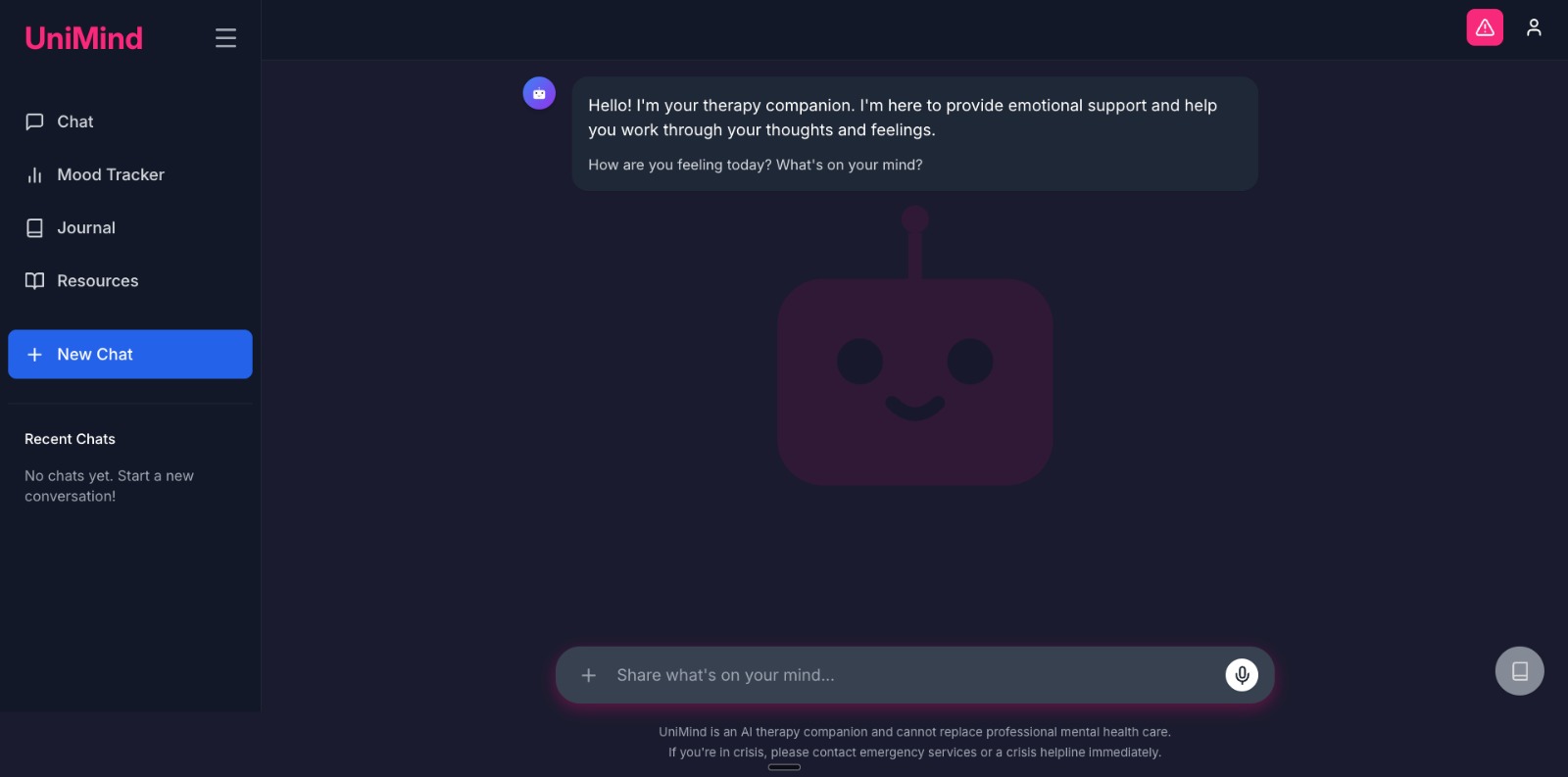
UI screenshots
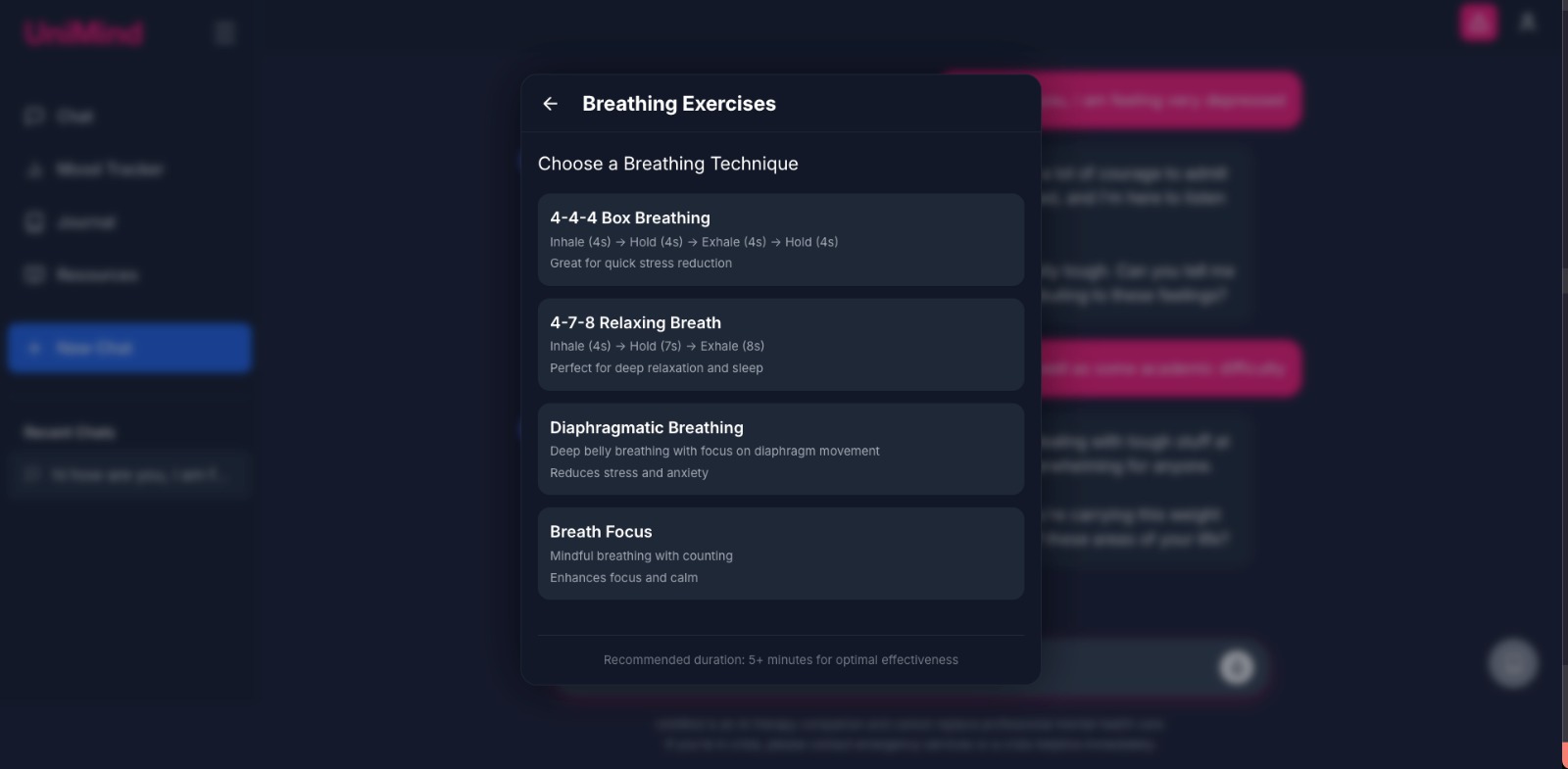
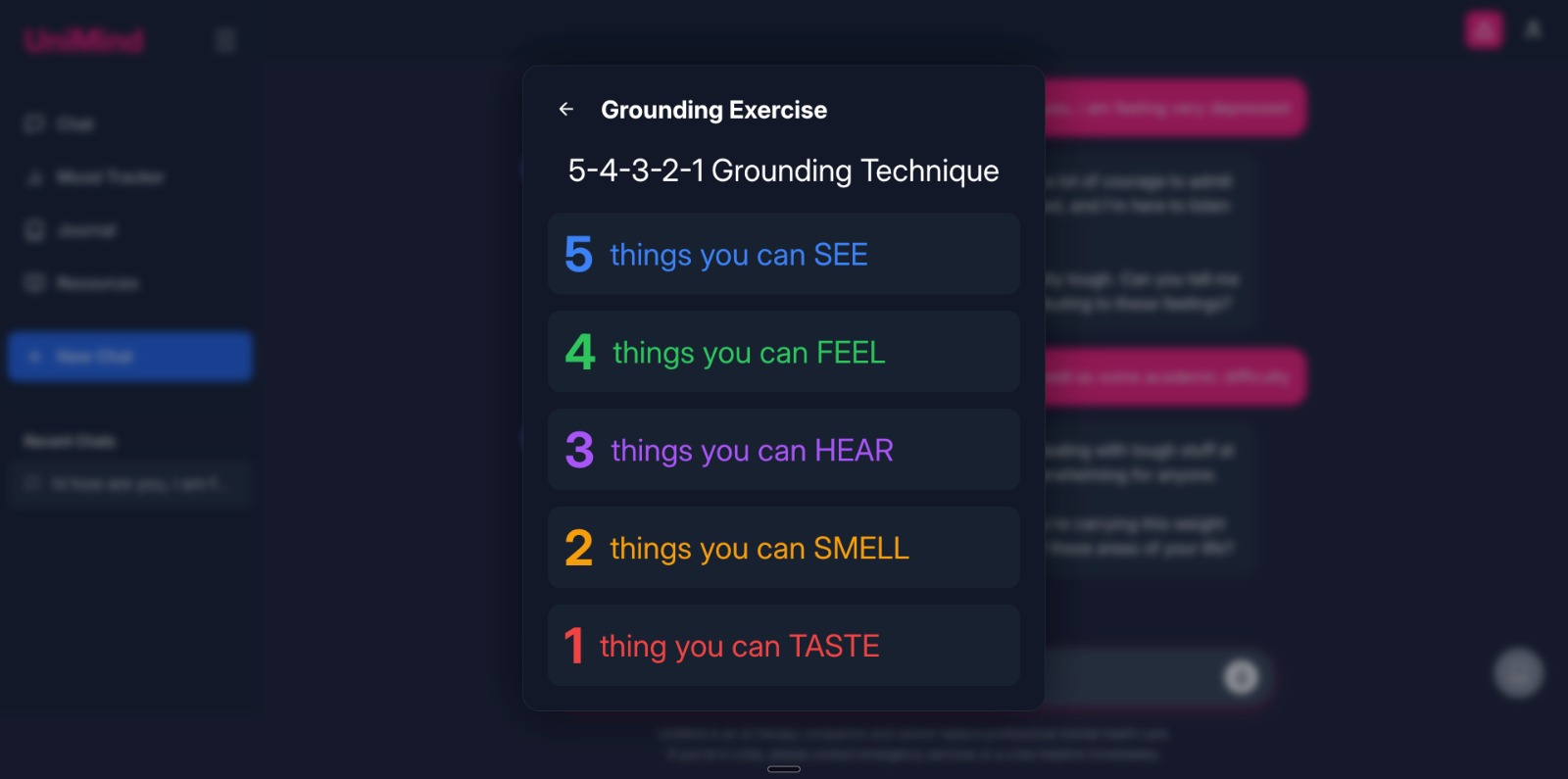
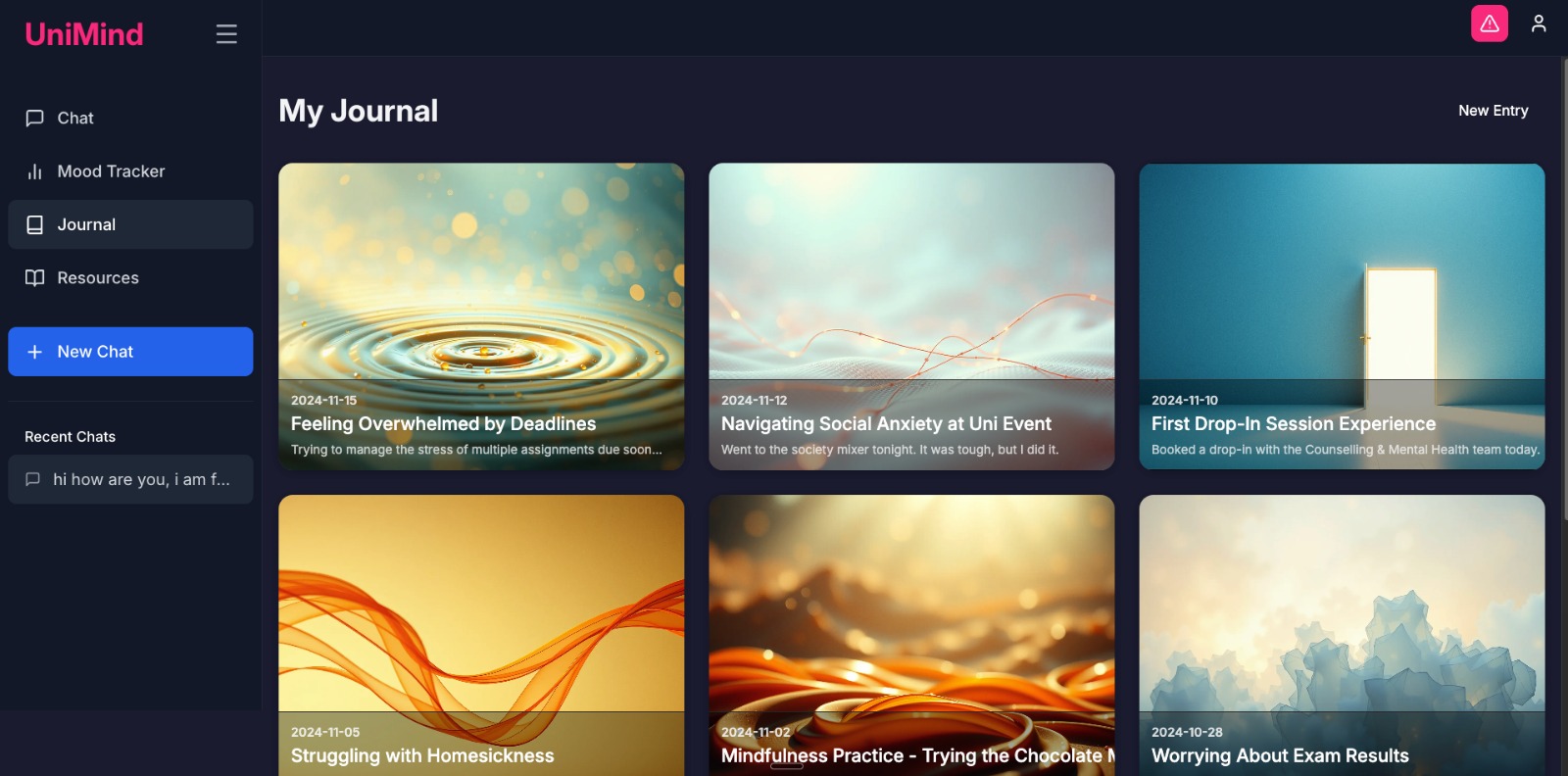
Formal references
- UniMind Chatbot Legacy Approach
- AI Project Data Cleaning
- UniMind Chatbot Web App
- UniMind Chatbot iOS App